
Featured posts from the
Practical Reporting Blog
New to this blog? The selection of posts below are representative of the types of topics normally covered.
For further reading, see all posts sorted by month.
Featured

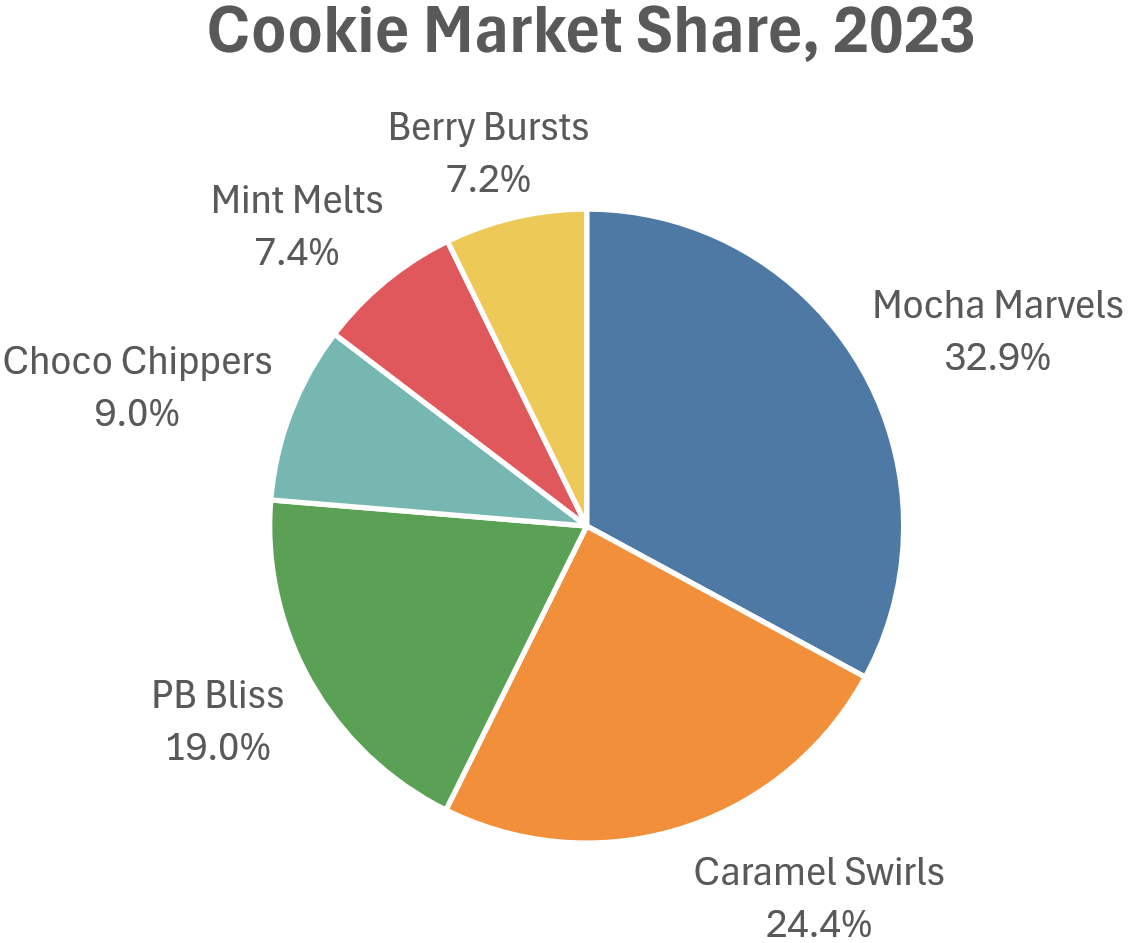






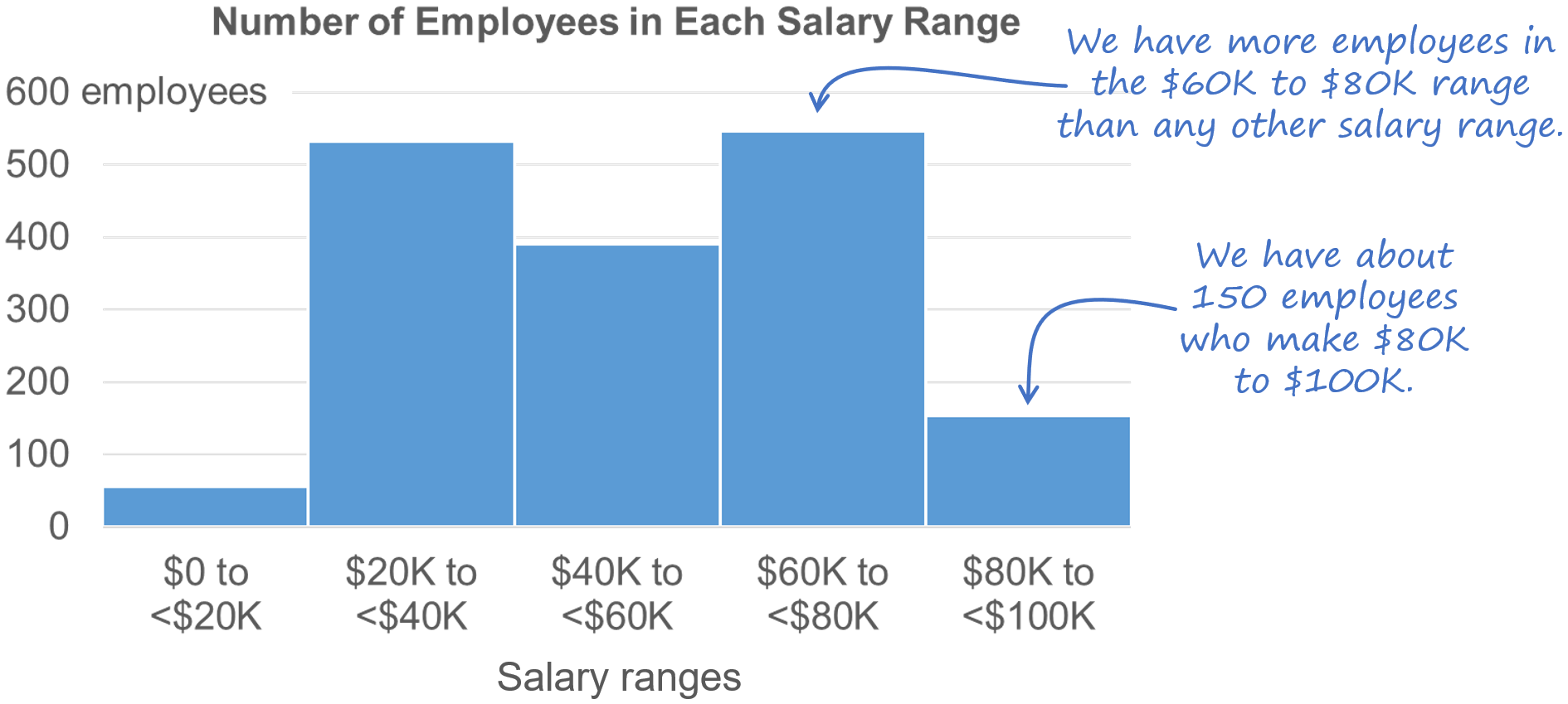
I don't use radar graphs because more informative and familiar chart types such as heatmaps and overlapping cycles charts can always communicate the same insights.